
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 리액트 네이티브
- 깃 연동
- 모두의네트워크
- 모두의 네트워크
- HTTP
- 스터디
- 문자열
- 백준 5525번
- 리액트 네이티브 시작하기
- 리액트 네이티브 프로젝트 생성
- 백준 4358번
- 데이터베이스
- 백준
- 팀플회고
- 깃 터미널 연동
- 네트워크
- 자바
- 깃허브 로그인
- 머신러닝
- SQL
- 딥러닝
- 모두를위한딥러닝
- 지네릭스
- 백준 4358 자바
- 모두를 위한 딥러닝
- 데베
- 백준 4949번
- 정리
- 깃허브 토큰 인증
- React Native
- Today
- Total
솜이의 데브로그
스터디 ) 모두를 위한 딥러닝 lec 7~9 정리 본문
<Lec 7 정리>
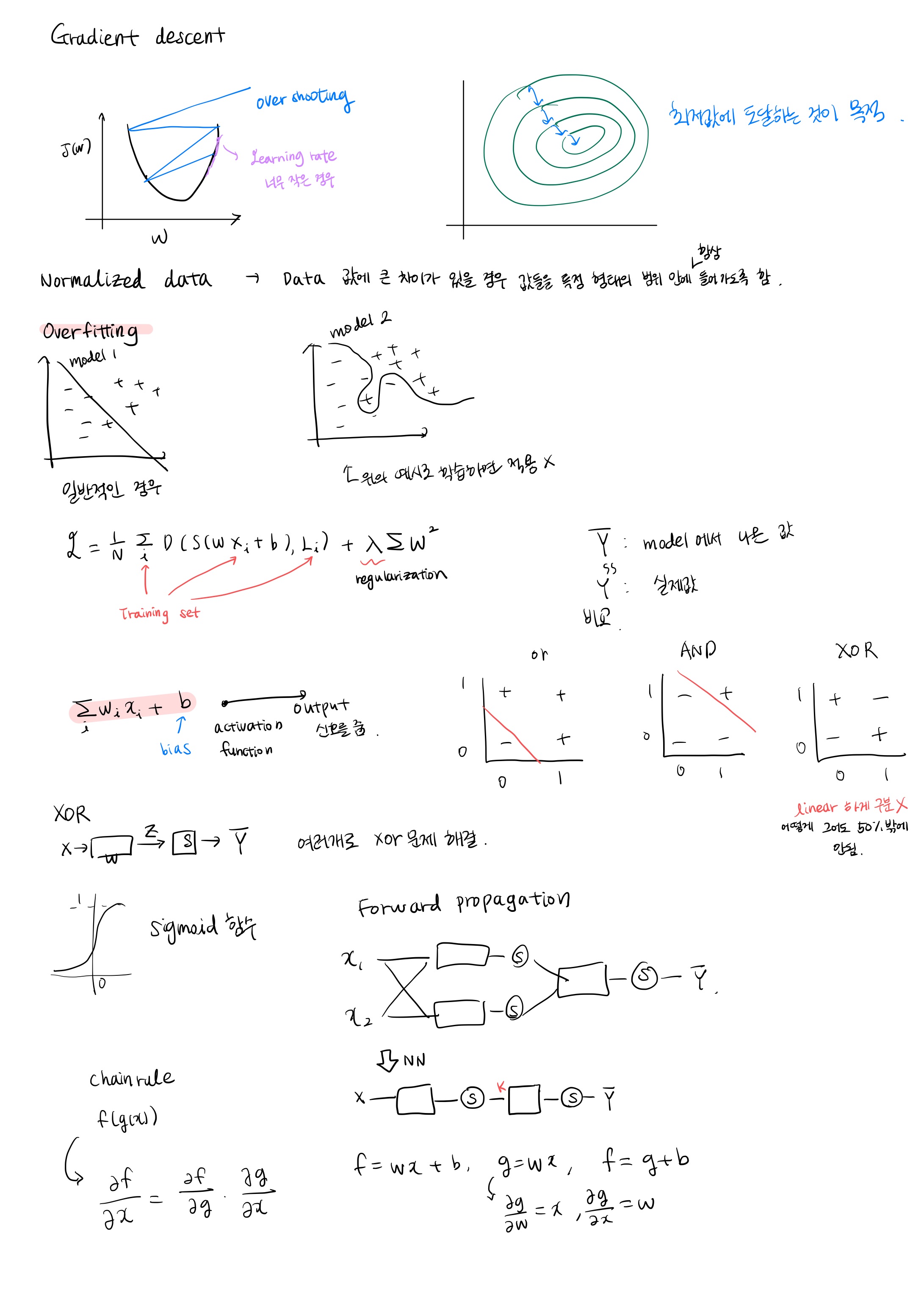
Learning rate, 가지고 있는 데이터를 선처리하는 방법, overfitting 방지 방법
- Gradient descent에서 최소값 구할 때 learning rate라는 α값을 임의로 지정함.적당한 learning rate 값을 지정하는 것이 중요하다.
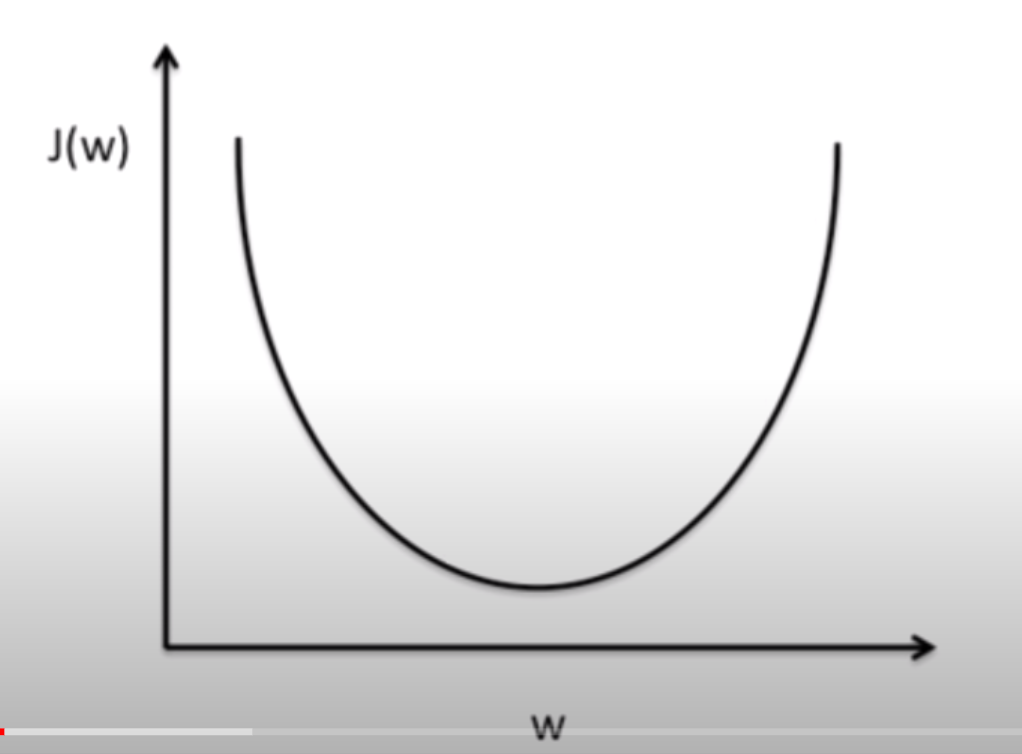
Learning rate 값이 너무 큰 경우 : step 이 너무 커져 그래프의 밖으로 튕겨 나갈 수 있다. 이를 'overshooting' 이라 함.
Learning rate값이 너무 작은 경우: 경사면을 너무 조금씩 이동해 바닥까지 내려가지 못하는 경우가 발생할 수 있다.
=> 방지하기 위해 cost 함수를 출력해보고 확인. 기울기가 거의 변하지 않는다면 learning rate을 조금 올려서 확인.
-Observe the cost function (처음 설정을 0.01 정도로 한 후 확인)
-Check it goes down in a reasonable rate (최저값을 향해 적당한 정도로 내려가는지 확인 후 아니라면 조정)
Data(X) preprocessing for gradient descent
- Normalized data : Data 값에 큰 차이가 있을 경우 Normalize 해야함. data 값들이 어떤 형태의 범위 안에 항상 들어가도록 함.
- zero-centered data : Data의 중심이 0으로 가도록 조정.
Standardization
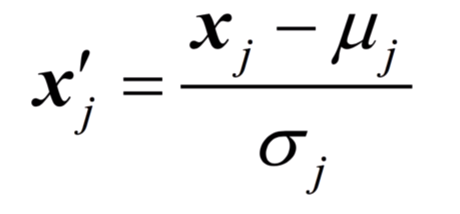
평균과 분산 이용하여 다음과 같은 식으로 표준화한다.
X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()파이썬 이용 시 다음과 같은 식으로 표현 가능.
Overfitting
- 학습 데이터에 딱 맞는 모델을 만들어 냈는데, 실제 데이터를 통해 학습 해 보면 잘 맞지 않는 경우.
줄이는 법 - training data 의 양을 늘린다. - Feature 의 갯수를 줄인다. (중복 된 것이 있을 경우 줄이기) - Regularization 일반화 : 우리가 가지고 있는 weight 을 너무 큰 값을 가지지 않도록 함.
모델이 얼마나 성공적으로 예측 할 수 있을 지 평가 : Training set 과 Test set 을 나누어 결과 비교한다.Original Set : Training + Validation + Testing 으로 구성 되어 있음.Training, Validation 의 과정을 거친 후 Testing 단계로 가야함.
Online learning 학습 방법 - 학습 시킨 결과들을 model에 남아있도록 함. 기존에 가지고 있는 Data에 추가로 학습.
Accuracy 정확도 - 실제 결과 값. 모델이 가지고 있는 값과 실제 결과 값이 얼마나 일치하는지? - 이미지 인식의 정확도는 대부분 95% ~ 99%
<Lec 8 정리>
어떠한 input x 에 weight 의 곱의 합 + bias = ∑ x·w + b
이 값들을 Activation Functions 을 통해 output으로 신호를 보낸다.
Perceptrons
Backpropagation (Hinton)
- 네트워크가 주어진 입력 (Training set)을 가지고 출력을 만들어 낸다. 이 때 w,b 조절. 출력에서 error를 찾아 반대로 전달시킨다.
- 더 복잡한 형태의 예측이 가능해짐.
Convolutional Neural Networks
- 고양이가 그림을 보게 한 뒤 그림의 형태에 따라 활성화 되는 뉴런을 발견 -> 우리의 신경망 세포는 일부분을 담당하고, 이 세포들이 나중에 조합 되는 것이라 생각.
- 부분부분을 잘라 인식 후 나중에 합치는 방식.
- 90% 이상의 성능을 보여줌. 미국에서는 이를 통해 책을 자동으로 읽는 기능을 만들어 사용함.
문제점
- Backpropagation algorithm이 앞에 있는 에러를 뒤로 보낼 때 의미가 갈 수록 약해져 거의 전달 되지 않고 학습을 시킬 수 없게 됨. 많이 할 수록 성능 저하.
- 다른 알고리즘들의 등장.
CIFAR (Canadian Institute for Advanced Research) : neural network 이라는 연구를 계속 진행함.
Breakthrough 논문 발표. 초기값을 잘 선택한다면 학습 할 수 있다는 것을 보여줌 -> Deep netwrok, Deep Learning 으로 이름을 바꿈.
Deep API Learning - 자연어로 시스템에 입력을 줬을 때 시스템이 자동적으로 어떤 API를 어떤 순서로 써야하는지 나열. - 아직까지는 프로그램이 바로 생성되지는 않지만 약 65%의 정확도로 올라왔다.
<Lec 9 정리>
XOR 문제 해결법 - And, Or 은 linear line으로 구분이 가능하지만 Xor 은 선형으로 구분하는 선을 찾을 수 없다.
Neural Net - 여러개의 망을 사용.
w·x + b 를 여러개 사용하여 y1, y2 값을 낸 다음 그 둘을 sigmoid 함수를 사용하여 y hat의 결과를 확인한다.
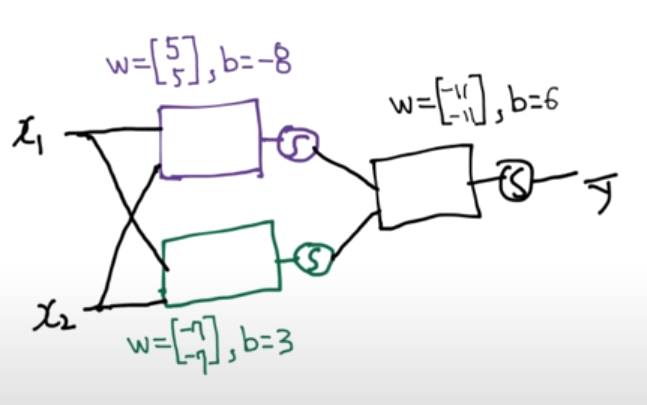
NN : Forward propagation 의 그림에서 첫번째 계산을 합침. 각각 연산을 해서 수식으로 처리.
K(X) = sigmoid (XW1+ B1)Yhat = H(X) = sigmoid (K(x)W2 + b2)
순간변화율 = 미분 값.
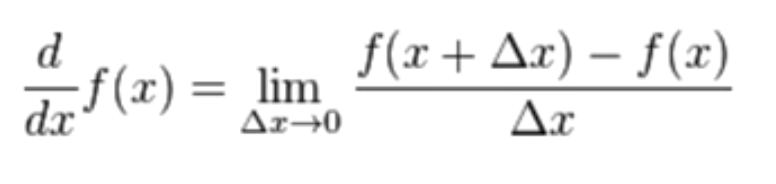
Partial derivative : 내가 미분하는 값을 제외한 나머지를 상수 취급.
Back propagation (chain rule)
f = wx + b, g = wx, f= g+b
- > 이를 각각 편미분 한다.
1) forward (주어진 값을 대입해 입력시킨다.) : 학습 데이터로부터 값을 얻는다.
2) backward (실제 값으로 확인) : 예측값과 실제값을 비교해 오류를 찾고, 출력 조정한다.
필기 정리
'Machine Learning' 카테고리의 다른 글
| 실습 ) Kaggle house price 실습 (0) | 2021.04.05 |
|---|---|
| 실습 ) Titanic 실습 (0) | 2021.03.29 |
| 스터디 ) 모두를 위한 딥러닝 lec10~12 정리 (0) | 2021.03.22 |
| 스터디 ) 모두를 위한 딥러닝 lec 4~6 정리 (0) | 2021.03.15 |
| 스터디 ) 모두를 위한 딥러닝 lec 1~3 정리 (0) | 2021.03.15 |



