
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 모두를위한딥러닝
- 정리
- 깃허브 토큰 인증
- 리액트 네이티브 시작하기
- React Native
- 백준
- 지네릭스
- 문자열
- 리액트 네이티브 프로젝트 생성
- 깃 연동
- 모두의 네트워크
- 딥러닝
- 팀플회고
- 깃허브 로그인
- 백준 5525번
- 머신러닝
- 모두를 위한 딥러닝
- 데이터베이스
- SQL
- 백준 4358 자바
- 데베
- 리액트 네이티브
- HTTP
- 자바
- 모두의네트워크
- 네트워크
- 백준 4358번
- 깃 터미널 연동
- 스터디
- 백준 4949번
- Today
- Total
솜이의 데브로그
스터디 ) 모두를 위한 딥러닝 lec10~12 정리 본문
<Lec 10 정리>
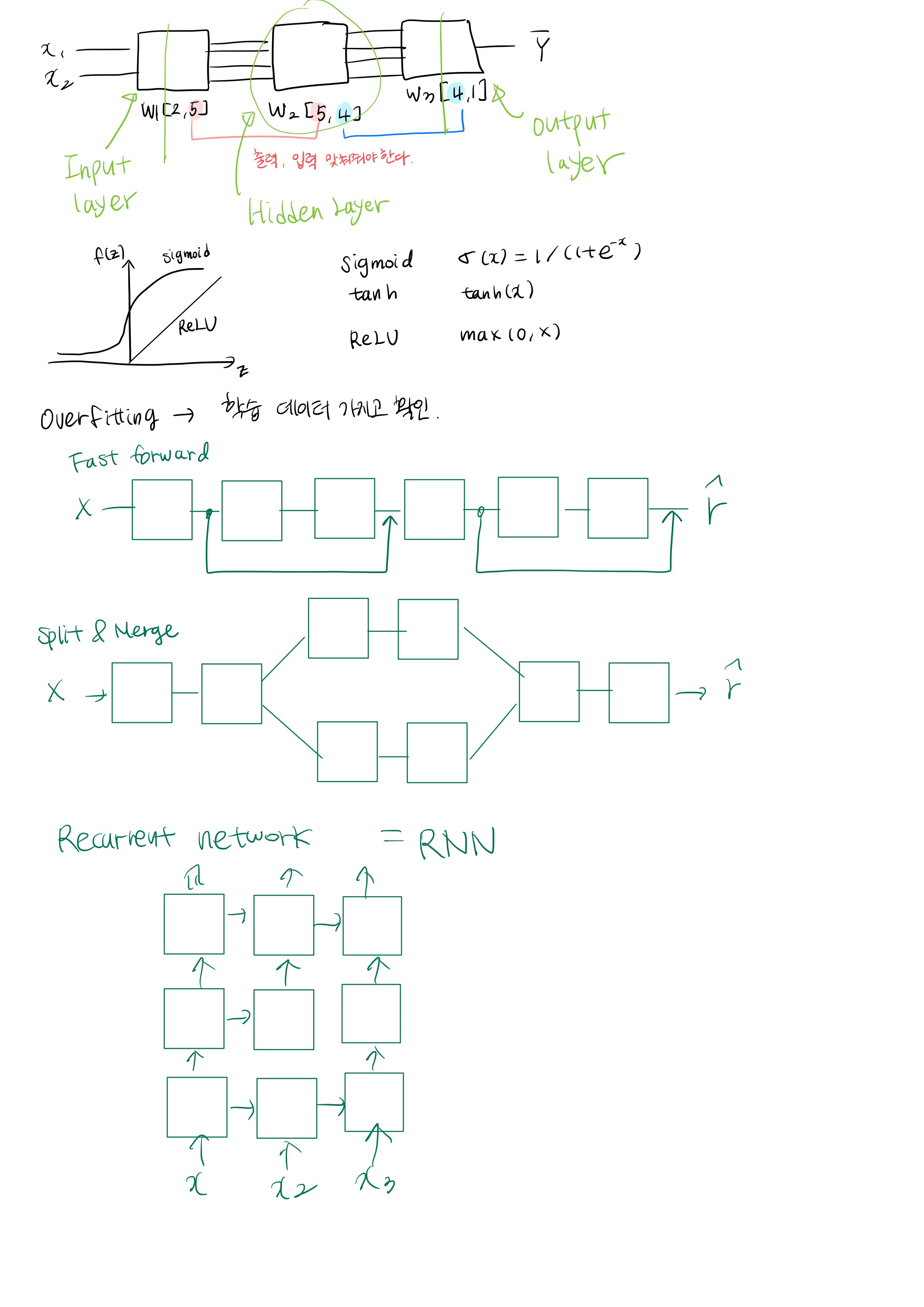
Sigmoid function 을 network 에서는 Activation function 이라고 많이 부른다.
- Layer가 여러 개 있을 때 처음 들어가는 부분은 Input layer 출력 부분은 output layer, 그리고 가운데는 Hidden Layer라고 한다.
- Layer가 여러 개 있을때 선행하는 앞 lyaer의 output과 그 바로 뒤의 input이 일치해야한다.
Backpropagation (lec 9-2 내용)
- 결과 값에 미친 영향을 알기 위해 각각의 값을 미분. 여기서 Sigmoid 함수를 사용하는 경우 : 미분을 사용해 결과에 미치는 정도를 파악하고 출력을 조정. 이 때 Sigmoid 함수를 사용하면 0~1 사이의 값이 출력이 되므로 제대로 된 값을 계산하지 못함. 이를 Vanishing Gradient 이라 함. - 최종 단 근처에 있는 경사나 기울기는 나타나지만, 앞으로 갈 수록 경사도가 사라짐.
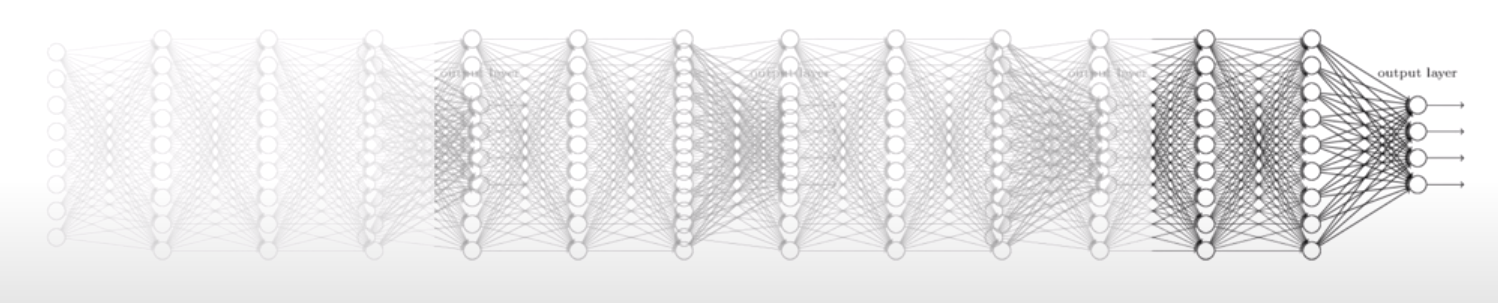
=> Layer에서 Sigmoid 함수 대신 ReLU 라는 함수를 사용한다. 하지만 마지막 단에선 sigmoid 함수를 사용한다. 0~1 사이 값을 출력해야 하기 때문.
Weight 초기화 모든 weight 을 0으로 초기화하면 모든 기울기가 0이 되므로 모든 gradient가 사라진다. → 그러므로 모든 값을 0으로 초기화하면 안됨. => RBM 을 이용해 초기화 해야 한다.
RBM : 가지고 있던 x 값과 생성된 x' 의 값을 비교함. 이 차이가 최소가 되도록 weight 을 조정.
- 층이 여러개 존재하는 경우 각 layer 를 반복하여 weight를 초기화 시킨다.
Drop out - 랜덤하게 어떤 뉴런들을 끊어낸 후 훈련한다. (뉴런들 삭제) - 마지막에 끊어냈던 뉴런들을 동원 해 예측한다. → overfitting 해결 가능. 더 좋은 성능.
Ensemble (앙상블)
- 독립적으로 학습시켜 만든 러닝 모델을 합친 모델이다.
- 더 좋은 성능으로 만들 수 있다. (대략 4~5% 향상 가능.)
네트워크 구조
- Fast forward : 여러개의 Layer 가 있을 때 몇 단을 건너 뛰도록 하는 구조.
- Split & Merge : 하나의 모델로 훈련시키다 여러개로 합치는 구조.
- Recurrent network : 옆으로도 Layer가 증가하면서 재귀적으로.
<Lec 11 정리>
Convolutional Neural Networks (CNN)
- 부분을 나누어 읽은 후 전체를 합치는 기법.
<예시>
1) 32*32*3 이라는 image를 입력.
2) 5*5*3 filter를 본다. (필드의 크기는 임의로 입력 가능.)
3) 위의 필터는 궁극적으로 하나의 값을 의미함. = 한 점만 뽑아내 출력한다.
4) 위의 출력 값을 weight으로 지정해 전체 그림을 훑는다. (몇 칸씩 움직일지를 'stride'라 하는데, 이 값은 임의로 설정)
5) 전체 그림이 몇개의 값을 모았는지를 계산. (ex : 7*7 input 에서 3*3 filter를 사용하면 5*5 output 이 나온다.)
=> Output size = (N-F) / stride + 1
(여기서 N은 input image의 크기, F 는 Filter 의 size)
위의 예시와 같은 경우 image가 점점 작아지는데, 그렇게 되면 정보를 잃어버린다.
→ Padding 이라는 개념 사용.
Padding : 그림이 너무 작아지는 것을 방지, 모서리 부분을 네트워크에 알려줌. 결과적으로 입력의 이미지와 출력의 이미지 사이즈를 같게 만들어준다.
Actiation maps
- 깊이가 필터의 개수인 출력을 가짐. (여러개의 filter를 가지고 있음)
- 값이 ( a, b, c) 형태로 나오는데 여기서 a,b 는 filter의 사이즈, c는 개수를 의미함.
- 이 activation maps에 convolution을 여러번 적용하며 반복한다.
Pooling layer (Sampling)
- 이미지에서 filter 처리 해 Convolution Layer를 만들어냄. 여기서 한 layer만 뽑아낸다.
- 이미지를 resize 함 (작게 만들기) = 이를 Pooling 이라 함.
- 위의 값들을 다시 쌓는다. Sampling 한 것들을 모으는 형태
→ Max Pooling : 픽셀 모음에서 가장 큰 값을 고른다.
Convolution → ReLU →Convolution →ReLU →Pooling →...계속반복
마지막에서 Pooling 작업을 한 후 원하는 출력값에 맞도록 조정.
<Lec 12 정리>
RNN
Sequence data : 현재의 state 가 그 다음 state 에 영향을 미친다.
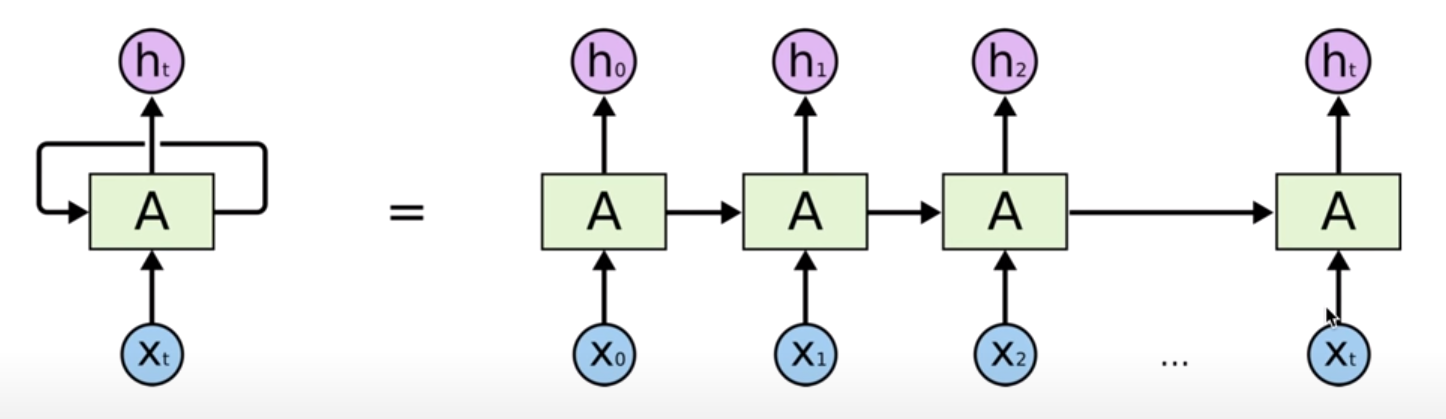
앞의 결과 값이 그 다음 계산에 영향을 미친다.
ht 가 new state, xt 가 input vector 라고 하는 경우 다음과 같은 식으로 표현.
$$h_t=f_w(h_{t-1},x_t)$$
위의 식에 wx를 넣으면 다음과 같은 형태가 된다.
$$h_t = tanh(W_{hh}h_{t-1}+W_{xh}x_t), y_t=W_{hy}\cdot h_t$$
예시)
'hello'를 출력하는 경우
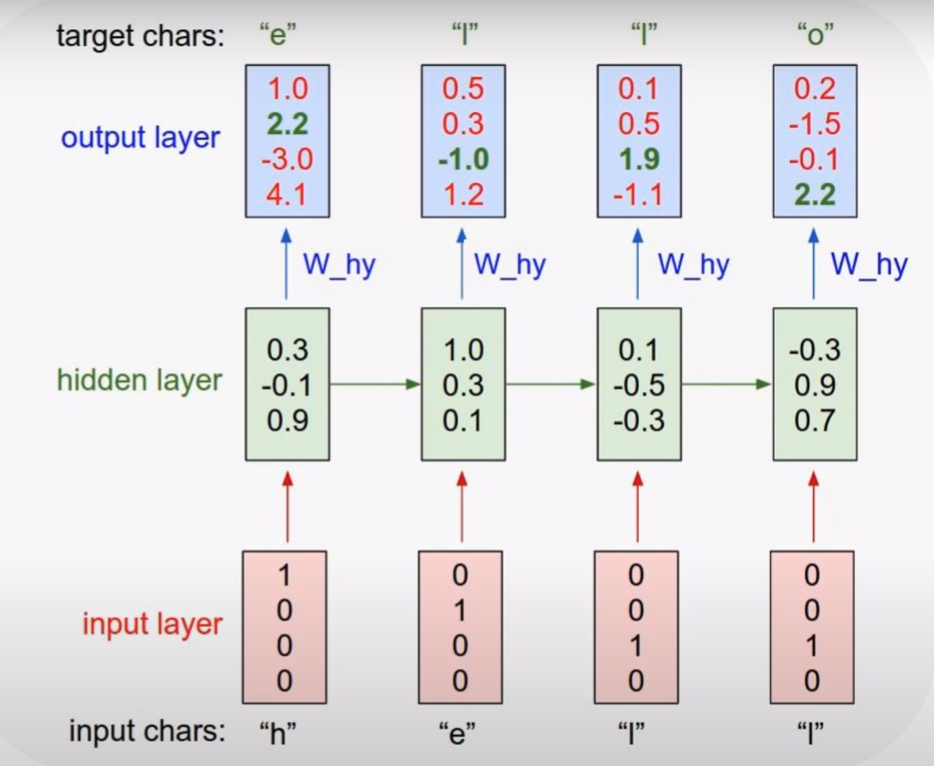
1 ) input layer 에 각각 자리에 해당 하는 값을 1로 설정. 각 알파벳에 맞는 input vector 를 설정한다.
2 ) Hidden layer 1 에서 input 'h'를 바탕으로 값을 출력한다.
3 ) Hidden layer 2 에서 Hidden layer 1 과 'e'를 input 으로 값을 출력한다.
4 ) 그 뒤에도 순차적으로 해당 값의 확률들을 출력값으로 갖는다.
RNN 활용 사례 ) Language Modeling (연관 검색어), Sppech Recognition (음성 인식), Machine Translation (번역기),
Conversation Modeling/Question Answering (채팅 봇 등), Image/Video Captioning
one-to-one / one to many / many to one / many to many 방법이 있음.
Multi-Layer RNN : 여러개의 layer를 두어 더 복잡한 학습이 가능한 RNN.
필기 정리
'Machine Learning' 카테고리의 다른 글
| 실습 ) Kaggle house price 실습 (0) | 2021.04.05 |
|---|---|
| 실습 ) Titanic 실습 (0) | 2021.03.29 |
| 스터디 ) 모두를 위한 딥러닝 lec 7~9 정리 (0) | 2021.03.22 |
| 스터디 ) 모두를 위한 딥러닝 lec 4~6 정리 (0) | 2021.03.15 |
| 스터디 ) 모두를 위한 딥러닝 lec 1~3 정리 (0) | 2021.03.15 |



