
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 팀플회고
- 스터디
- 리액트 네이티브 시작하기
- 깃 터미널 연동
- 딥러닝
- 데베
- HTTP
- 자바
- 리액트 네이티브 프로젝트 생성
- 모두를위한딥러닝
- 모두의 네트워크
- 리액트 네이티브
- 백준 4358 자바
- 머신러닝
- 모두를 위한 딥러닝
- 네트워크
- 깃허브 로그인
- 데이터베이스
- 백준 4358번
- 백준 5525번
- 지네릭스
- 백준
- 모두의네트워크
- 백준 4949번
- React Native
- 깃허브 토큰 인증
- 깃 연동
- 문자열
- 정리
- SQL
- Today
- Total
솜이의 데브로그
실습 ) Titanic 실습 본문
Kaggle 에서 데이터 셋 다운받기.
Titanic - Machine Learning from Disaster | Kaggle
Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
위의 링크에서 test.csv 와 train.csv 데이터를 다운 받을 수 있다.
각 파일을 엑셀에서 확인하면 각 항목들은 다음과 같다.
| Variable | Definition |
| Survived | 생존 여부 |
| Pclass | 티켓 클래스 |
| Name | 탑승자 이름 |
| Sex | 성별 |
| Age | 나이 |
| Sibsp | 탑승한 형제 자매 / 배우자 수 |
| Parch | 탑승한 부모 / 자녀의 수 |
| Ticket | 티켓 번호 |
| Fare | 요금 |
| Cabin | 캐빈 번호 |
| Embarked | 승선지(항구) |
1. 데이터 불러오기

다음과 같이 파일들을 불러온다.
2. 데이터 분석
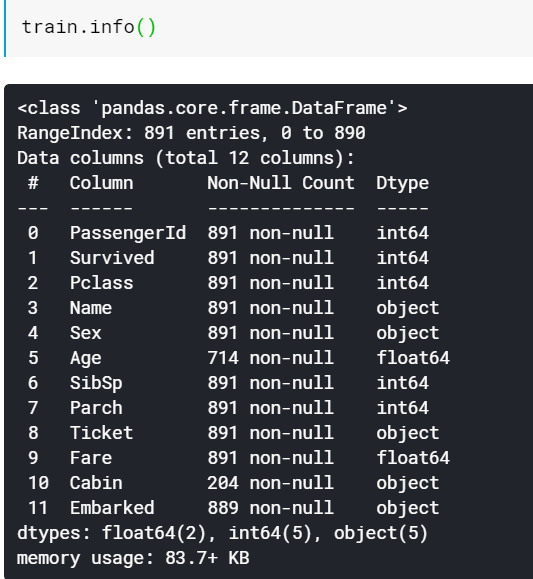
train 데이터에는 총 891개의 항목이 있는 것을 확인 할 수 있다. 이 중 비어있는 항목의 개수를 확인한다.
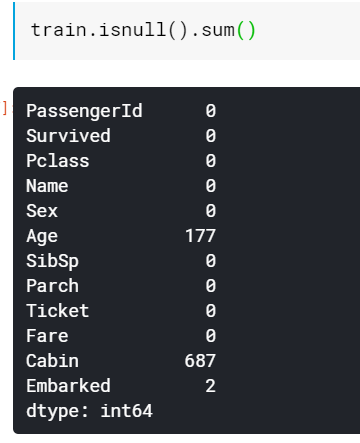
다음과 같은 방법으로 Age 항목에 177개의 항목, Cabin 에 687개의 항목, Embarked에 2개의 항목이 비어있음을 알 수 있다.
비어있는 항목 중에서
Age 의 경우, 결측치가 그렇게 많지 않고 생존 여부에 영향을 많이 미치므로 채워넣어야 한다.
Cabin의 경우 결측치가 너무 많으므로 항목을 제거하는 것이 낫다고 판단한다.
Embarked 의 경우 결측치가 2개밖에 없으므로, 아무 값으로 채워넣는다.
<그래프 분석>

matplotlib 와 seaborn 라이브러리를 이용해 생존자 칼럼과 다른 항목들의 상관관계를 알아보자.
def pie_chart(feature):
feature_ratio = train[feature].value_counts(sort=False)
feature_size = feature_ratio.size
feature_index = feature_ratio.index
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()
plt.plot(aspect='auto')
plt.pie(feature_ratio, labels=feature_index, autopct='%1.1f%%')
plt.title(feature + '\'s ratio in total')
plt.show()
for i, index in enumerate(feature_index):
plt.subplot(1, feature_size+1, i+1, aspect='equal')
plt.pie([survived[index],dead[index]], labels=['Survived', 'Dead'], autopct='%1.1f%%')
plt.title(str(index) + '\'s ratio')
plt.show()
pie_chart('Sex')
pie_chart('Pclass')
pie_chart('Embarked')파이 차트로 표현해보자
1) 성별
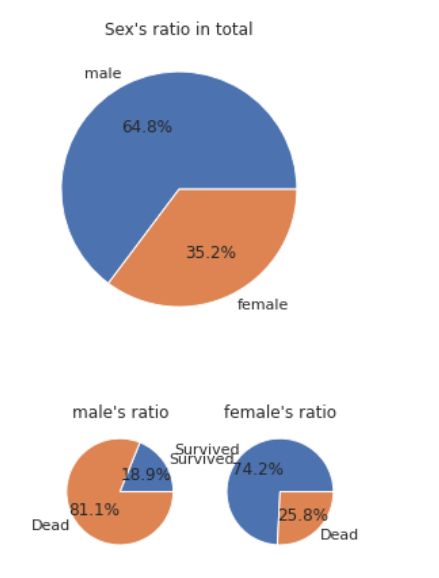
배에 남성이 여성보다 많았음을 알 수 있고, 남성보다 여성의 생존비율이 높음을 확인 할 수 있다.
2) 티켓 클래스, 즉 사회적 위치를 확인 할 수 있다.
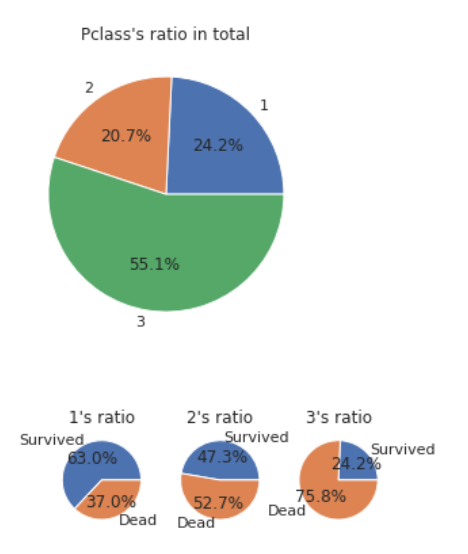
3등급인 사람들의 수가 가장 많았으며, 등급이 높을수록 생존률이 높다는 것을 확인할 수 있다.
3) Embarked, 배의 탑승 항구

S 선착장에서 탑승한 사람이 가장 많았음을 확인 할 수 있으며, C 선착장에서 탄 사람들은 비교적 생존률이 높으며 Q와 S 선착장에서 탄 사람들은 그렇지 않다는 것을 확인 가능하다.
이제 다른 데이터들을 Bar chart 형태로 시각화해보자.
def bar_chart(feature) :
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()
df=pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind='bar', stacked=True, figsize=(10,5))
bar_chart("SibSp")
bar_chart("Parch")
1)SibSp = 형제 자매와 배우자 수

형제나 배우자와 함께 배에 탔을 경우 생존한 사람의 비율이 크고, 그렇지 않은 경우의 사람들은 생존비율이 적었다는 것을 확인 할 수 있다.
2)Parch = 부모/자녀의 수
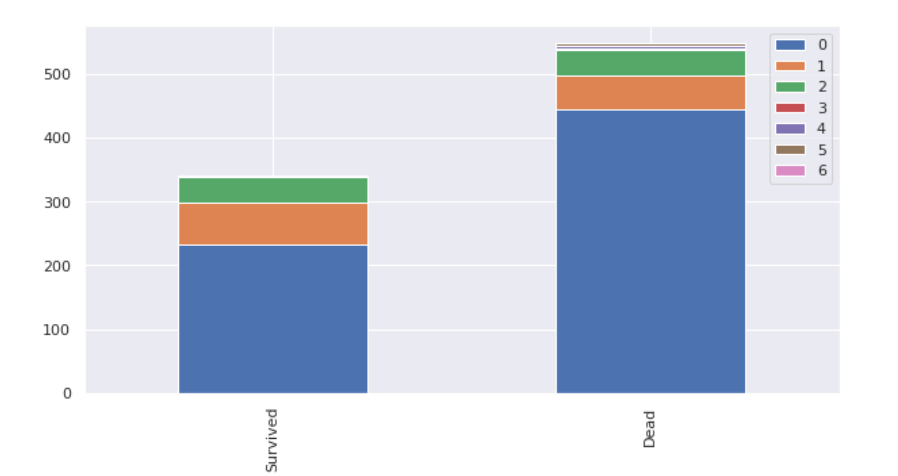
2명 이상의 부모나 자식과 함께 배에 탔을 경우 생존률이 더 높았다는 것을 확인 가능하다.
종합해보자면, 여성일수록, Pclass가 높을수록, C 선착장에서 탔을 수록, 형제/배우자/부모/자녀 와 함께 배를 탔다면 생존률이 높았다는 것을 알 수 있다.
데이터 전처리
1) 위의 과정에서 관련이 없다고 판단한 Cabin, Ticket 의 값들을 삭제한다.2) Name, Sex, Embarked 의 값들은 숫자로 변경한다.3) Age 에 비어있는 null 데이터들을 채워넣는다.4) Age 값의 범위를 줄인다.5) Fare의 값의 범위를 줄인다.
train = train.drop(['Cabin'], axis=1)
test = test.drop(['Cabin'], axis=1)
train = train.drop(['Ticket'], axis=1)
test = test.drop(['Ticket'], axis=1)
train.head()Drop 함수를 이용하여 Cabin 과 Ticket 값을 삭제한다.
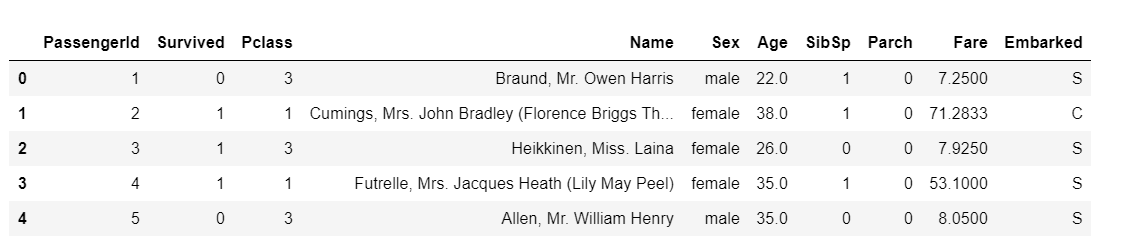
필요 없는 값들이 삭제되었음을 확인 할 수 있다.
Embarked 값 가공
train = train.fillna({"Embarked": "S"})
train['Embarked'].value_counts()앞서 Embarked 칼럼에서 두개의 값이 null 임을 확인하였으므로, 이를 최빈값 S로 채워준다.
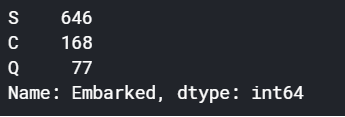
값을 확인해보면 2개의 null 값이 S로 들어갔음을 알 수 있다.
그 후 각 값 S, C, Q 를 숫자로 변경한다. 머신러닝은 문자를 인식하지 않기 때문이다.
embarked_mapping = {"S" :1, "C": 2, "Q" :3}
train['Embarked'] = train['Embarked'].map(embarked_mapping)
test['Embarked'] = test['Embarked'].map(embarked_mapping)
train.head()위와 같이S는 1로, C는 2로, Q는 3으로 가공했다.
train 데이터 뿐만 아니라 test 데이터도 같이 가공해줘야한다.

Embarked 데이터가 숫자로 바뀌었음을 확인 할 수 있다.
Name 값 가공
combine = [train, test]
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
pd.crosstab(train['Title'], train['Sex'])문자열 파싱을 통해 가공한다. 각 이름에 남자와 여자를 뜻하는 Mr, Mrs, Miss 등을 확인한다.
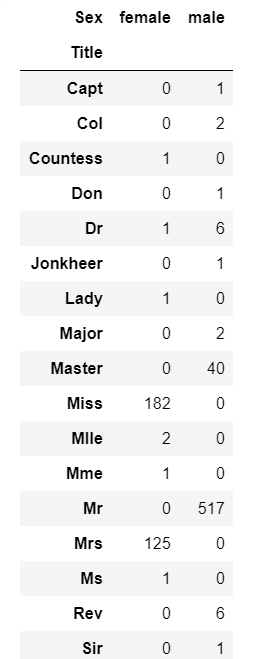
다음 표를 확인해보면 데이터가 대부분 정확하게 나오는 것을 볼 수 있다.최대한 줄여보면 Mr, Mrs, Miss, Royal, Rare, Master 6개로 줄일 수 있다. 이를 바탕으로 각 생존률 평균을 알 수 있다.
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace(['Countess', 'Lady', 'Sir'], 'Royal')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()
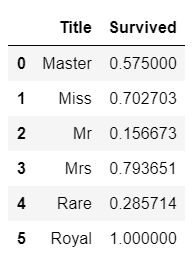
Royal은 모두 생존한 것을 확인 가능하다. 이 데이터를 바탕으로 1부터 6까지 매핑하여 숫자로 변경한다.
title_mapping = {"Mr": 1, "Miss": 2, "Mrs":3, "Master": 4, "Royal": 5, "Rare": 6}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
train.head()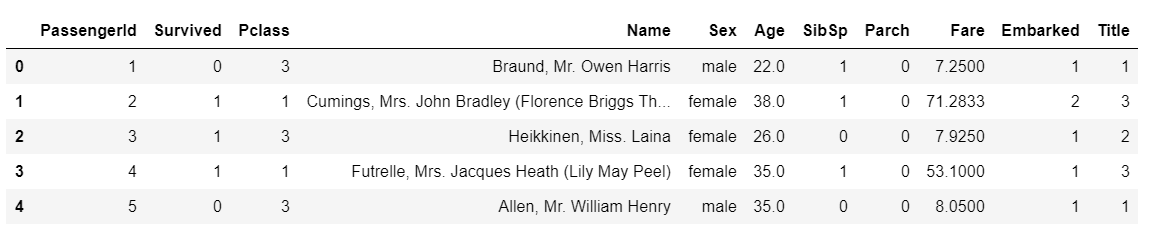
위의 표를 통해 Title 값이 추가되었음을 확인 가능하다.그럼 이제 train 함수의 name과 passengerID는 더이상 필요 없으므로 drop 함수를 이용해 삭제한다.
train = train.drop(['Name', 'PassengerId'], axis=1)
test = test.drop(['Name'], axis=1)
combine = [train,test]
train.head()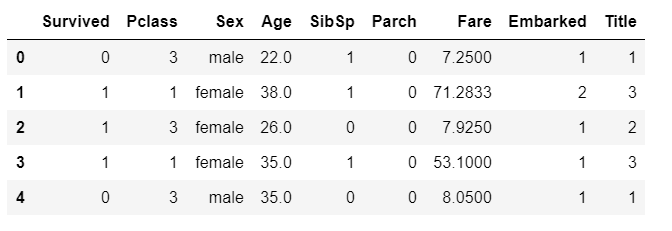
또 Sex의 값 역시 map 함수를 이용해 숫자로 변경한다. male은 0, femlae은 1로 변경.
sex_mapping = {"male":0 , "female": 1}
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map(sex_mapping)
train.head()
Age 값 가공
먼저 Age의 null 값을 -0.5 채워 넣은 후, cut 함수를 사용해 AgeGroup 을 만든다.cut 함수는 각 구간의 값을 특정 값으로 정의해주는 함수이다.
train['Age'] = train['Age'].fillna(-0.5)
test['Age'] = test['Age'].fillna(-0.5)
bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf]
labels = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior']
train['AgeGroup'] = pd.cut(train["Age"], bins, labels = labels)
test['AgeGroup'] = pd.cut(test["Age"], bins, labels = labels)
train.head()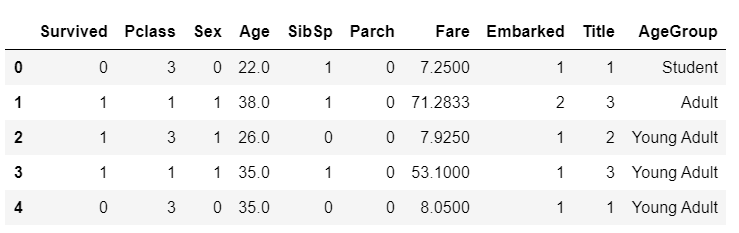
bar_chart('AgeGroup')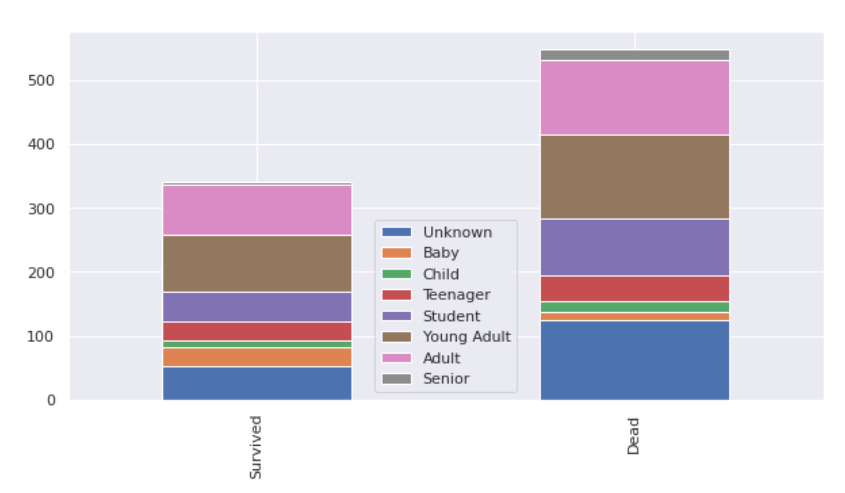
null의 값의 unknown이 대부분 사망한 것으로 나왔고 많은 부분을 차지하고 있다. 그러므로 Title에 따라서 연령을 추측해 넣는다.(정확도가 떨어질 수 있음)
age_title_mapping = {1: "Young Adult", 2: "Student", 3: "Adult", 4: "Baby", 5: "Adult", 6: "Adult"}
for x in range(len(train["AgeGroup"])):
if train["AgeGroup"][x] == "Unknown":
train["AgeGroup"][x] = age_title_mapping[train["Title"][x]]
for x in range(len(test["AgeGroup"])):
if test["AgeGroup"][x] == "Unknown":
test["AgeGroup"][x] = age_title_mapping[test["Title"][x]]
train.head()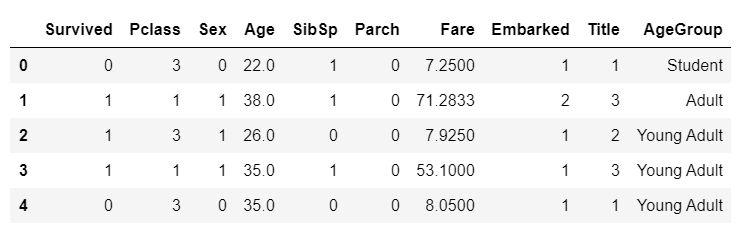
이제 AgeGroup을 숫자로 바꾼 후, 필요 없는 Age 칼럼은 삭제한다.
age_mapping = {'Baby' : 1, 'Child': 2, 'Teenager': 3, 'Student': 4, 'Young Adult': 5, 'Adult': 6, 'Senior': 7}
train['AgeGroup'] = train['AgeGroup'].map(age_mapping)
test['AgeGroup'] = test['AgeGroup'].map(age_mapping)
train = train.drop(['Age'], axis=1)
test= test.drop(['Age'], axis=1)
train.head()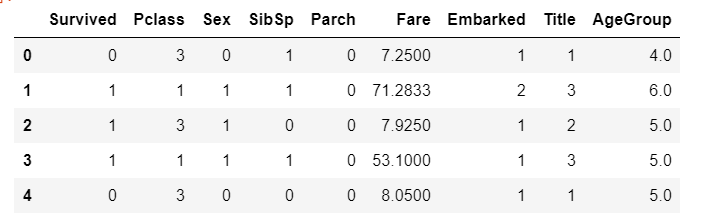
Fare 가공
train['FareBand'] = pd.qcut(train['Fare'], 4, labels = [1,2,3,4])
test['FareBand'] = pd.qcut(test['Fare'], 4, labels = [1,2,3,4])
train = train.drop(['Fare'], axis=1)
test = test.drop(['Fare'], axis=1)
train.head()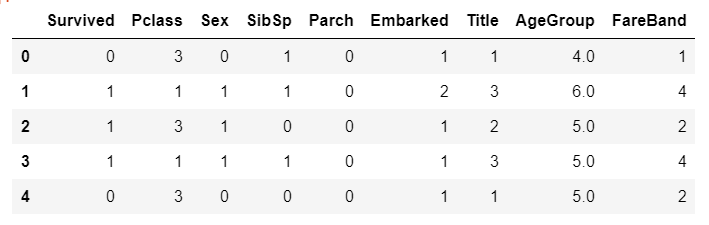
위와 같이 qcut 함수를 사용한다. 4개의 범위로 나누어 1,2,3,4 로 바꾸어준다.
3. 데이터 모델링
Train Set을 X와 Y값으로 나누어준다.
train_data = train.drop('Survived', axis=1)
target = train['Survived']
train_data.shape, target.shape
위의 값에서 X값은 Train_data 이고, Y 값은 target 이라고 볼 수 있다.
train.info()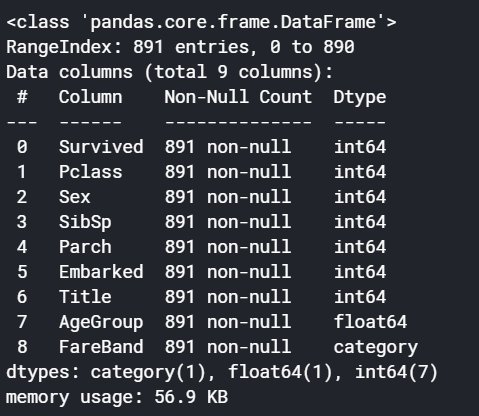
Train 데이터의 정보에서 null 값이 없음을 확인한다.
sklearn 라이브러리를 사용한다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
import numpy as np
K-fold 를 통해 교차 검증할 예정인데, K-fold CV를 활용하여 Train set 데이터를 10개의 fold로 나눈다.
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
k_fold = KFold(n_splits=10, shuffle=True, random_state=0)
랜덤 포레스트 알고리즘을 사용하여 예측한다.
clf = RandomForestClassifier(n_estimators=13)
clf
scoring = 'accuracy'
score = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
print(score)
round(np.mean(score)*100, 2)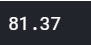
다음과 같은 방식으로 평균 정확도가 81.37점이 나온 것을 확인 할 수 있다.
최종 결과물을 submission.csv 파일을 생성해 저장한다.

다음과 같이 저장 후 캐글에 제출한다.
파이썬 한지 오래돼서 다 까먹었었는데 공부 열심히해야겠다고 느꼈다 ㅎ_ㅎ
'Machine Learning' 카테고리의 다른 글
| YOLOv5 학습 및 연속적인 이미지 (영상) detect 하기 (2) | 2021.08.15 |
|---|---|
| 실습 ) Kaggle house price 실습 (0) | 2021.04.05 |
| 스터디 ) 모두를 위한 딥러닝 lec10~12 정리 (0) | 2021.03.22 |
| 스터디 ) 모두를 위한 딥러닝 lec 7~9 정리 (0) | 2021.03.22 |
| 스터디 ) 모두를 위한 딥러닝 lec 4~6 정리 (0) | 2021.03.15 |



