
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 문자열
- 백준 4358번
- 깃허브 로그인
- 정리
- 머신러닝
- 모두의네트워크
- 모두의 네트워크
- 백준 5525번
- 데베
- 리액트 네이티브 시작하기
- HTTP
- React Native
- 깃 연동
- 지네릭스
- 스터디
- 백준 4949번
- 자바
- 모두를 위한 딥러닝
- SQL
- 딥러닝
- 팀플회고
- 데이터베이스
- 깃 터미널 연동
- 네트워크
- 깃허브 토큰 인증
- 백준 4358 자바
- 리액트 네이티브 프로젝트 생성
- 리액트 네이티브
- 백준
- 모두를위한딥러닝
- Today
- Total
솜이의 데브로그
YOLOv5 학습 및 연속적인 이미지 (영상) detect 하기 본문
Yolo란? You Only Look Once 의 약자로 객체 탐지 모델이다. 학습시키고자하는 객체들의 이미지를 라벨링 후 학습시키면 해당 객체를 탐지할 수 있도록 하는 모델이다.
검색해보면 현재 버전5 까지 나와있고, 버전 3 까지는 레퍼런스가 상당히 많은데 4, 5는 만든 사람도 다르다하고 논문 여부 등에 대해서도 정확하지가 않다.
하지만 비교적 최근에 나온 버전5는 속도나 성능 측면에 있어서 유리하다고 생각했기 때문에 우리는 yolov5를 사용하기로 했다!
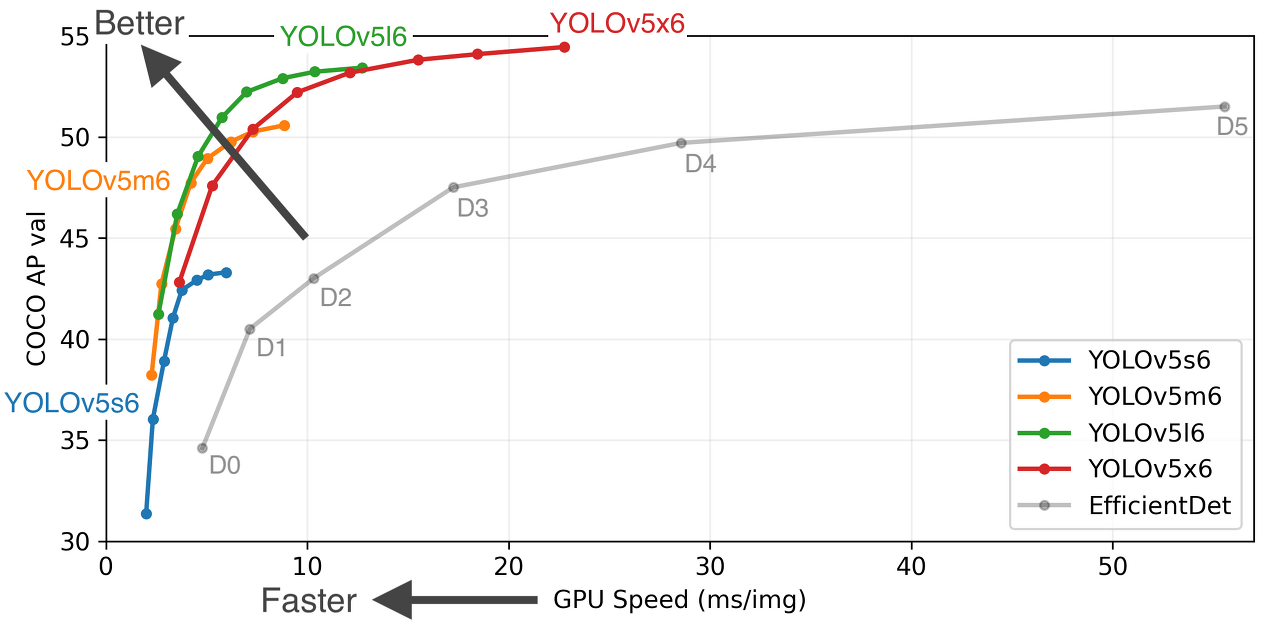
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
일단 사용한 yolo v5 모델은 위의 깃헙에서 클론 가능하다.
1. 학습시키기
1) 환경 셋팅
나는 colab에서 진행하였다. (로컬이나 가상환경에서 진행해도 거의 동일)
위 깃허브에 가면 colab에서 사용 할 때 기본적인 튜토리얼을 제공해준다. coco 파일을 이용하여 학습 및 탐지 할 수 있는 튜토리얼을 제공하는데, 해당 코드들을 참고하면 어떻게 사용하면 될 지 대충 감이 올것이다.
일단 나도 기본적인 틀은 튜토리얼에서 변형하여 사용하였다.
!git clone https://github.com/ultralytics/yolov5 # clone repo
%cd yolov5
%pip install -qr requirements.txt # install dependencies
import torch
from IPython.display import Image, clear_output # to display images
clear_output()
print(f"Setup complete. Using torch {torch.__version__} ({torch.cuda.get_device_properties(0).name if torch.cuda.is_available() else 'CPU'})")
먼저 위의 깃허브 레포를 클론해오고, pytorch 깔고, 필요한 모듈들을 설치한다.
클론해오면 필요한 pre-trained model 등이 모두 들어올것이다. 이 모델들은 학습을 시킬 때 사용할 것인데, 뒤에 설명하겠다.
2) 데이터셋 불러오기
그럼 이제 학습시키고자 하는 데이터셋을 불러와야한다.
나는 colab에서 진행했으므로, 구글 드라이브를 마운트해서 데이터셋을 불러왔다.
from google.colab import drive
drive.mount('/content/drive')(로컬에서 진행할 경우 그냥 데이터셋의 경로만 잘 보면 됨)
이때 중요한것은 데이터셋 폴더의 구조이다.
데이터 폴더 이름 (dataset)
- images
-train
-validation
-labels
-train
-validation
다음과 같은 구조로 형성해야한다.
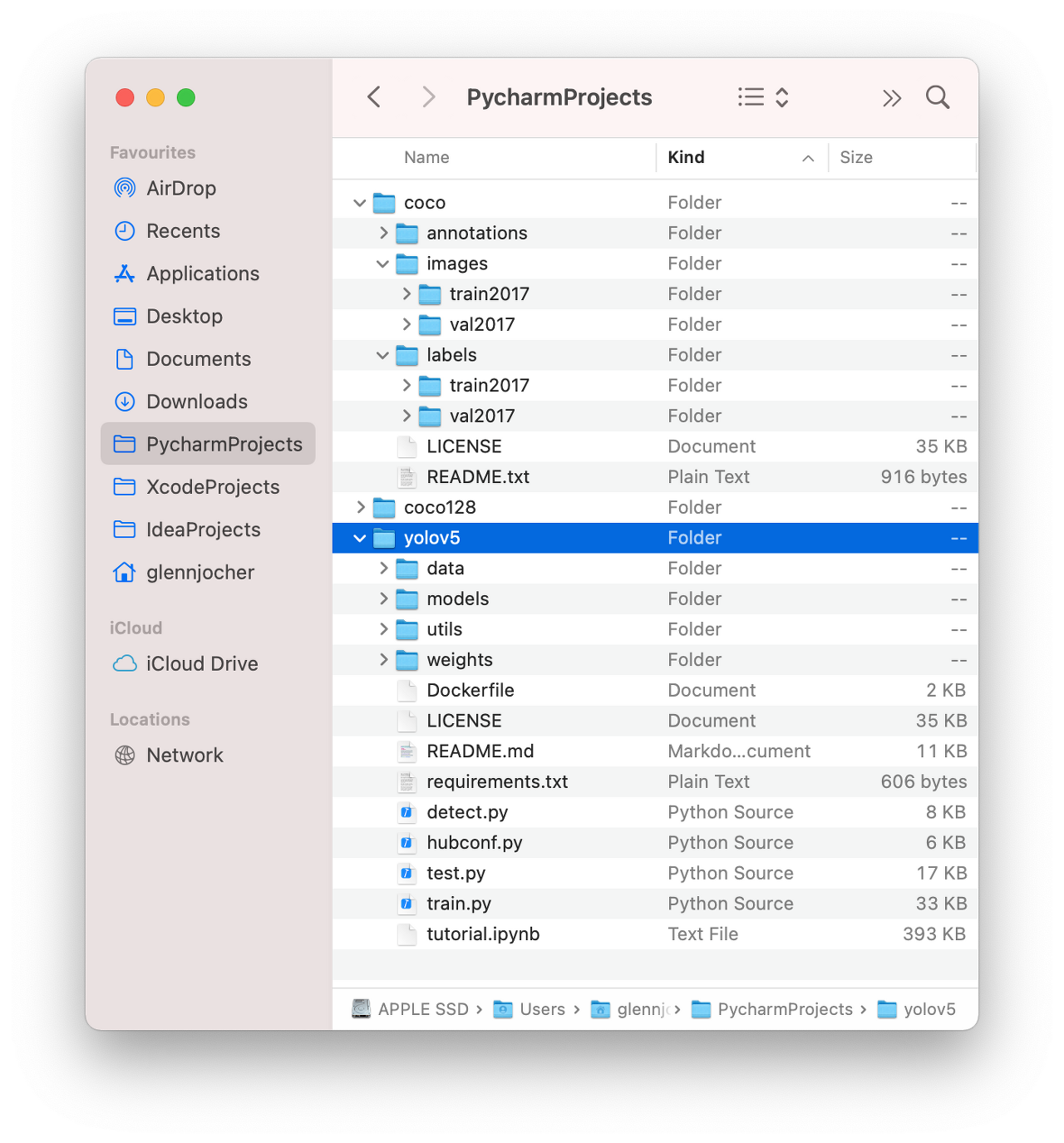
위 사진에서 보자면 데이터 폴더 이름이 coco 이고, 그 아래에 각각 images, labels 디렉토리가 위치하는걸 볼 수 있다. 또 각각 디렉토리에 아래에 train과 validation이 위치한다.
이때 label이란, 학습시키고자 하는 객체 이미지 내에서 존재하는 영역을 표시한 것이다. 이미지와 같은 이름으로 객체 위치의 좌표가 저장된 텍스트파일이다.
우리는 라벨링을 MakeSense를 이용해 진행했다.
Make Sense
www.makesense.ai
3) yaml 파일 작성하기
다음 단계로는 우리가 학습시킬 대상의 클래스 이름, 클래스 개수, 그리고 학습 데이터의 경로를 지정해야한다!
data 디렉토리 아래에서 coco.yaml (또는 coco128.yaml) 파일을 찾아보면 어떤식으로 작성하면 될 지 감이 올것이다.
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ] # class names이 파일을 수정해도 좋고, 참고하여 다른 이름으로 파일을 생성해도 좋다. 주석에 이미 설명이 다 나와있긴하지만,
- path : 학습시키고자 하는 데이터의 이름이다. 위에 데이터셋 디렉토리 구조 예시에서 봤던 coco가 이에 해당한다.
- train : path 경로 아래에 images 폴더의 train 디렉토리 경로를 입력한다.
- val: path 경로 아래에 images 폴더의 val (validation) 디렉토리 경로를 입력한다.
- nc : 학습시키고자 하는 클래스의 개수. 나는 8개의 클래스를 학습시킬것이므로 8을 입력했다.
- names : 학습시키고자 하는 클래스의 이름. 라벨링 한 목록에 0, 1, 2, 3,.. 순으로 되어있다면 같은 순서로 클래스 명을 입력해야한다.
나는 test 항목은 제거하고 쟉성했다. 작성 후 dataset.yaml 이나 custom.yaml 등등 원하는 이름으로 저장한다.
4) 모델 선택
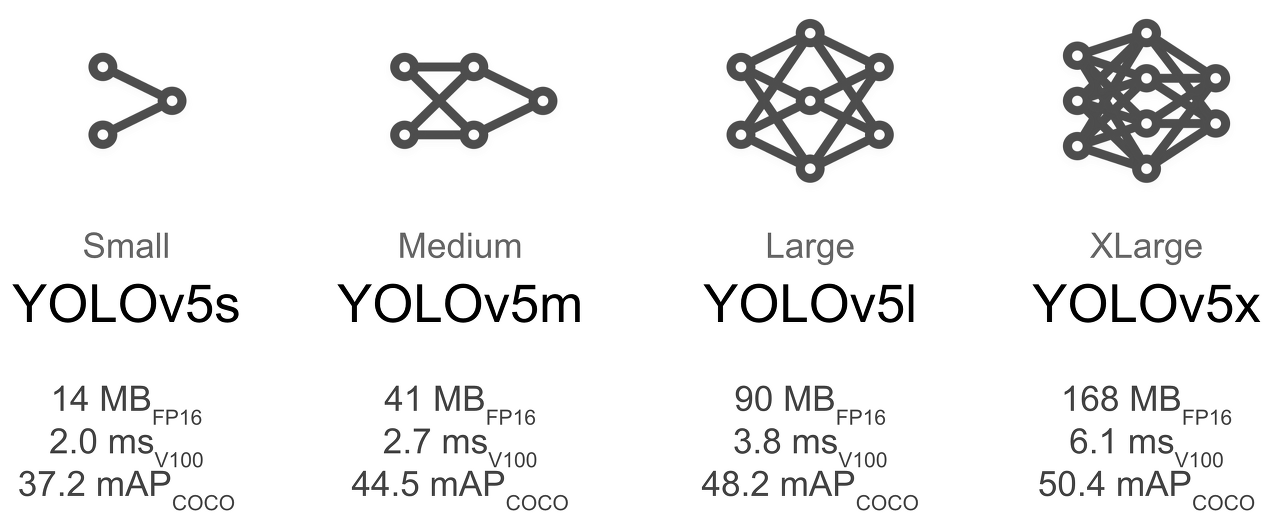
이제 학습시킬때 사용할 pre trained model을 선택한다. 클론해오면 yolov5s.pt, yolov5m.pt 등의 파일을 볼 수 있을텐데, 그것들이 이미 학습된 모델이다. 즉, 학습 파라미터들 (bias, weight)이 잘 초기화되어있는 파일들이다. 또 models 아래 가면 위 모델들의 아키텍처 파일들이 있다. (yolov5s.yaml 등)
yolov5 공식 깃허브 피셜 pretrained model 쓰는걸 권장한다고 하니 사용해보도록 하자ㅎ
위의 사진처럼 s 단계부터 x까지 있는것을 확인 가능한데, 왼쪽으로갈수록 가벼운 모델이고 오른쪽으로 갈수록 무겁다. 여기서 FPS란 Frame Per Second, 즉 초당 프레임수로, 1초당 얼마나 많은 프레임을 처리하느냐의 차이이다. 위의 스펙등을 참고하여 원하는 모델을 선택한다.나는 colab 에서 gpu 환경으로 돌려보았을 때, 데이터셋의 영향도 있었겠지만 m까지가 한계였던 것 같다. 그마저도 m은 램이 극도로 치솟아서 결국 s를 사용하여 학습시켰는데.. 여건이 된다면 무거운 모델 쓰는게 좋기는 할 듯!
5) 학습
자 이제 모두 다 셋팅했으면 학습을 시키자!
%cd /content/yolov5/
!python train.py --img 640 --batch 20 --epochs 30 --data custom_data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name yolov5s_results다음과 같은 명령어를 사용해 학습시킬 수 있는데, 명령어들을 설명하자면 다음과 같다.
--img: input 이미지의 크기
--batch: 배치사이즈 (얼마나 묶어서 학습시킬지)
--epochs : 에포크 수 (대충 몇 번 학습시킬지)
--data : 위의 3번에서 만든 yaml 파일. 클래스 수, 이미지 경로 등을 지정.
--cfg : 모델 yaml 파일.
--weights : 4에서 선택한 pretrained model (weight)
--name : 학습 정보 결과를 저장할 이름
그 외에도 각자 필요한 옵션은 train.py 파일에 parse_opt()를 참고하여 사용하면 된다.
이렇게 실행하고나서 원하는 만큼 학습이 될 때까지 기다리면 weight 파일이 저장될것이다!
%load_ext tensorboard
%tensorboard --logdir /content/yolov5/runs/학습 결과 및 그래프 등은 텐서보드에 찍어서 확인 가능하다.
2. 탐지(detect) 하기
이제 잘 학습이 되었는지 확인을 해보자. 탐지가 잘 되는지 확인하기 위해 원하는 데이터를 넣고 detect 를 하면 된다.
from IPython.display import Image
import os
%cd /content/yolov5
!python detect.py --source /content/folder2 --img 640 --weights /content/best_4.pt
경로를 설정해 준 후, 위의 명령어를 입력한다. 이건 쉽다!
--source : 탐지하고자 하는 대상의 경로
--img : input image 사이즈
--weights : 위에서 내내 학습시켰던 결과물!! train.py 실행해서 나온 파일의 경로를 입력하면된다. 위와 같은 코드에서 파일이 yolov5 내에 있으면 파일 이름만 입력해도 되는데 나는 다른 경로에 있어서 경로 자체를 입력했다.
이 외에도 나는 --save-txt, --nosave 등의 옵션을 사용했는데, 이 역시 detect.py 코드 내의 함수에서 참고 가능하다.
여기서 나는 탐지하고자 하는 대상이 연속적인 이미지, 즉 영상이었다.그런데 찾아보니까 source 에 하나의 이미지를 넣거나, 영상 파일 자체를 넣는 케이스는 많은데 이렇게되면 탐지 결과 output이 영상의 형태로만 나와서 내가 원하는 결과를 얻지 못했다.내가 원했던건 영상에서 연속된 사진 (영상)을 탐지해서, 어느 초에 어느 이미지를 인식했는 지를 반환하는 결과였다.
그래서 일단 source 경로에 넣을 수 있는 형식들을 확인해보았다.
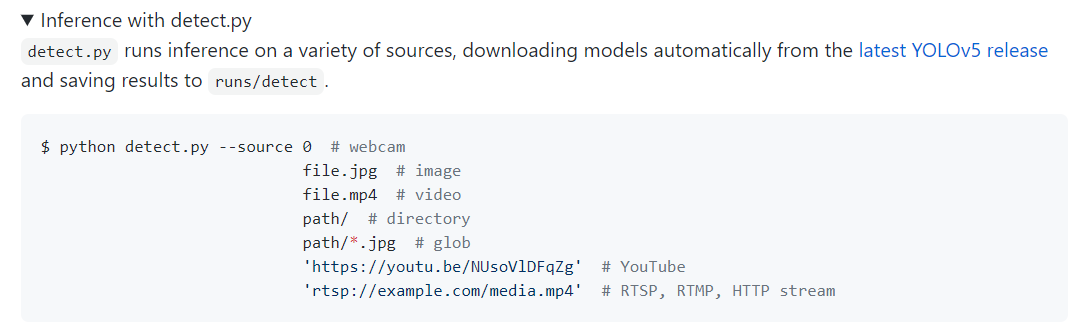
이걸 확인 안하고 한참 삽질했는데, 경로에 유튜브 링크도 가능하고 디렉토리도 가능하다.
그래서 영상을 ffmpeg을 이용해 자르고, 그 이미지들을 디렉토리에 저장한다음 source 경로에 해당 디렉토리를 넣었다.
원하는 만큼 fps 수를 설정해서 자르면 된다!
프레임 자르는 코드의 형식은 다음과 같다.
!ffmpeg -i https://www.youtube.com -vf fps=1 %3d.jpg대충 이런식으로 사용하고 링크자리에 원하는 영상을 넣으면 된다. 위의 코드는 fps 수를 1로 설정했다.
이렇게 잘린 프레임들이 있는 디렉토리를 source 코드에 넣고, detect.py 에서 결과를 json 형태로 가공하도록 수정 후 해당 결과 값을 반환하도록 했다.
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.사실 이건 내가 필요한 결과를 얻기 필요한 과정이므로, 영상 자체를 넣어 결과를 출력하고 싶다면 result 를 print 하는 방법에도 여러가지가 있으니 필요한 결과값 형태로 가공하여 사용하면 될 듯 하다.
(나는 pandas로 하는게 안됐는데 원인을 찾지못해서 그냥 detect.py 코드내에서 json 형식으로 저장하도록 수정해버렸다)
여기까지 완전 기초적이고 간단한 yolov5 학습 및 탐지하는 법!
'Machine Learning' 카테고리의 다른 글
| 실습 ) Kaggle house price 실습 (0) | 2021.04.05 |
|---|---|
| 실습 ) Titanic 실습 (0) | 2021.03.29 |
| 스터디 ) 모두를 위한 딥러닝 lec10~12 정리 (0) | 2021.03.22 |
| 스터디 ) 모두를 위한 딥러닝 lec 7~9 정리 (0) | 2021.03.22 |
| 스터디 ) 모두를 위한 딥러닝 lec 4~6 정리 (0) | 2021.03.15 |



